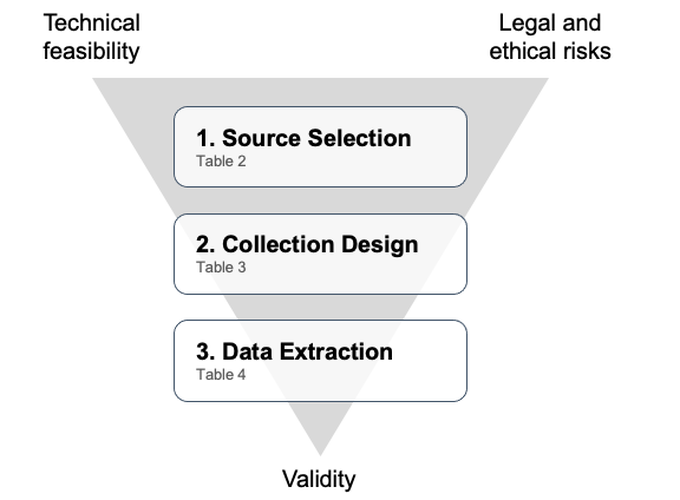
Marketing scholars increasingly use web scraping and Application Programming Interfaces (APIs) to collect data from the internet. Yet, despite the widespread use of such web data, the idiosyncratic and sometimes insidious challenges in its collection have received limited attention. How can researchers ensure that the datasets generated via web scraping and APIs are valid? While existing resources emphasize technical details of extracting web data, the authors propose a novel methodological framework focused on enhancing its validity. In particular, the framework highlights how addressing validity concerns requires the joint consideration of idiosyncratic technical and legal/ethical questions along the three stages of collecting web data: selecting data sources, designing the data collection, and extracting the data. The authors further review more than 300 articles using web data published in the top five marketing journals and offer a typology of how web data has advanced marketing thought. The article concludes with directions for future research to identify promising web data sources and to embrace novel approaches for using web data to capture and describe evolving marketplace realities.